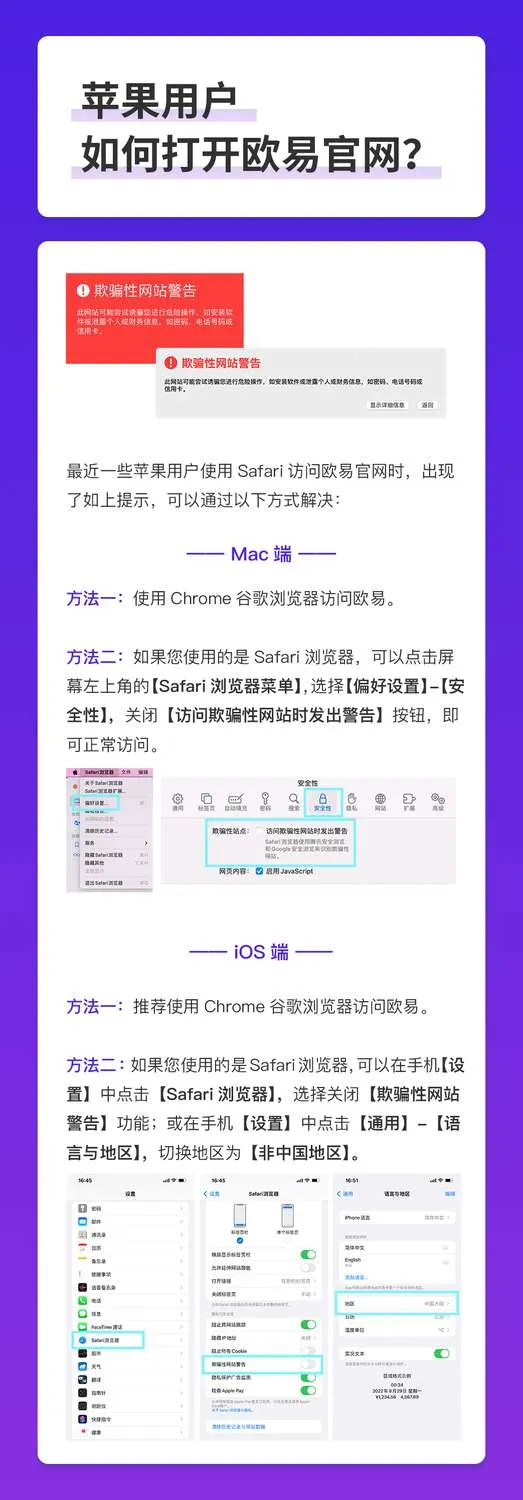
Google、Wolfram Alpha 和ChatGPT都通过单行文本输入字段与用户交互并提供文本结果。谷歌返回搜索结果,网页列表和文章(希望)提供与搜索查询相关的信息。Wolfram Alpha 通常提供与数学和数据分析相关的答案。
相比之下,ChatGPT 根据用户问题背后的上下文和意图提供响应。例如,您不能要求谷歌写故事或要求 Wolfram Alpha 编写代码模块,但 ChatGPT 可以做这些事情。
从根本上说,Google 的强大之处在于能够进行大量的数据库查找并提供一系列匹配项。Wolfram Alpha 的强大之处在于能够解析与数据相关的问题并根据这些问题执行计算。ChatGPT 的强大之处在于能够解析查询并根据世界上大多数基于数字可访问的文本信息(至少是 2021 年之前培训时存在的信息)生成完整的答案和结果。
在本文中,我们将了解 ChatGPT 如何生成这些完整的答案。我们将从查看 ChatGPT 操作的主要阶段开始,然后介绍使其全部运行的一些核心 AI 架构组件。
除了本文中引用的资源(其中许多是每种技术背后的原始研究论文)之外,我还使用 ChatGPT 本身来帮助我创建这个背景资料。我问了它很多问题。一些答案在本次讨论的总体背景下进行了解释。
ChatGPT运行的两个主要阶段
我们再用谷歌来打个比方。当您要求 Google 查找某些内容时,您可能知道它不会——在您询问的那一刻——出去搜索整个网络以寻找答案。相反,谷歌会在其数据库中搜索与该请求匹配的页面。Google 实际上有两个主要阶段:蜘蛛和数据收集阶段,以及用户交互/查找阶段。
粗略地说,ChatGPT 的工作方式相同。数据收集阶段称为预训练,而用户响应阶段称为推理。生成式 AI背后的魔力及其突然爆发的原因是预训练的工作方式突然被证明具有极大的可扩展性。
预训练人工智能
一般而言(因为深入了解细节需要大量的知识),人工智能使用两种主要方法进行预训练:监督和非监督。对于大多数 AI 项目,直到当前的生成式 AI 系统(如 ChatGPT)出现之前,都使用了监督方法。
监督预训练是一个模型在标记数据集上训练的过程,其中每个输入都与相应的输出相关联。
例如,人工智能可以在客户服务对话的数据集上进行训练,其中用户的问题和投诉被标记为客户服务代表的适当回应。要训练 AI,请提出诸如“如何重设密码?”之类的问题。将作为用户输入提供,并提供诸如“您可以通过访问我们网站上的帐户设置页面并按照提示操作来重置密码”之类的答案。将作为输出提供。
在有监督的训练方法中,整个模型被训练以学习可以准确地将输入映射到输出的映射函数。这个过程通常用于监督学习任务,例如分类、回归和序列标记。
正如您所想象的那样,这种扩展方式是有限制的。人类培训师必须在预测所有输入和输出方面走得更远。培训可能需要很长时间,而且主题专业知识有限。
但正如我们所知,ChatGPT 在主题专业知识方面几乎没有限制。你可以要求它为星际迷航中的迈尔斯奥布莱恩酋长写一份简历,让它解释量子物理,写一段代码,写一篇短篇小说,比较美国前总统的执政风格状态。
不可能预测所有会被问到的问题,所以 ChatGPT 真的不可能用监督模型进行训练。相反,ChatGPT 使用无监督预训练——这就是游戏规则的改变者。
非监督预训练是在没有特定输出与每个输入相关联的数据上训练模型的过程。相反,该模型经过训练以学习输入数据中的底层结构和模式,而无需考虑任何特定任务。该过程常用于无监督学习任务,例如聚类、异常检测和降维。在语言建模的上下文中,可以使用无监督预训练来训练模型以理解自然语言的句法和语义,从而可以在会话上下文中生成连贯且有意义的文本。
在这里,ChatGPT 看似无限的知识成为可能。因为开发人员不需要知道输入的输出,他们所要做的就是将越来越多的信息转储到 ChatGPT 预训练机制中,这称为 transformer-base 语言建模。
变压器架构
Transformer架构是一种用于处理自然语言数据的神经网络。神经网络通过互连节点层处理信息来模拟人脑的工作方式。将神经网络想象成曲棍球队:每个球员都有一个角色,但他们在具有特定角色的球员之间来回传球,所有球员共同努力得分。
Transformer 架构通过使用“ self-attention ”来处理单词序列,以在进行预测时权衡序列中不同单词的重要性。自注意力类似于读者可能会回顾前一个句子或段落以了解理解书中新单词所需的上下文的方式。转换器查看序列中的所有单词以了解上下文和单词之间的关系。
变压器由几层组成,每一层都有多个子层。两个主要的子层是自注意力层和前馈层。自注意力层计算序列中每个单词的重要性,而前馈层对输入数据应用非线性变换。这些层帮助转换器学习和理解序列中单词之间的关系。
在训练期间,transformer 被赋予输入数据,例如一个句子,并被要求根据该输入进行预测。该模型根据其预测与实际输出的匹配程度进行更新。通过这个过程,Transformer 学会理解序列中单词之间的上下文和关系,使其成为语言翻译和文本生成等自然语言处理任务的强大工具。
让我们先讨论输入 ChatGPT 的数据,然后看看 ChatGPT 和自然语言的用户交互阶段。
ChatGPT 的训练数据集
用于训练 ChatGPT 的数据集非常庞大。ChatGPT 基于GPT-3(Generative Pre-trained Transformer 3)架构。现在,缩写 GPT 很有意义,不是吗?它是生成的,意味着它生成结果,它是预训练的,意味着它基于它摄取的所有这些数据,并且它使用 transformer 架构来权衡文本输入以理解上下文。
GPT-3 在名为WebText2的数据集上进行了训练,该数据集包含超过 45 TB 的文本数据。当您可以以低于 300 美元的价格购买 16 TB 的硬盘驱动器时,45 TB 的语料库可能看起来并不那么大。但文本占用的存储空间比图片或视频少得多。
如此大量的数据使 ChatGPT 能够以前所未有的规模学习自然语言中单词和短语之间的模式和关系,这也是它能够如此有效地生成连贯且与上下文相关的用户查询响应的原因之一。
虽然 ChatGPT 基于 GPT-3 架构,但它已经针对不同的数据集进行了微调,并针对对话用例进行了优化。这允许它为通过聊天界面与之交互的用户提供更加个性化和引人入胜的体验。
例如,OpenAI(ChatGPT 的开发者)发布了一个名为Persona-Chat 的数据集,专门用于训练像 ChatGPT 这样的对话式 AI 模型。该数据集包含两个人类参与者之间超过 160,000 次的对话,每个参与者都分配了一个描述他们的背景、兴趣和个性的独特角色。这使 ChatGPT 能够学习如何生成个性化且与对话的特定上下文相关的响应。
除了 Persona-Chat 之外,还有许多其他用于微调 ChatGPT 的对话数据集。这里有一些例子:
- Cornell Movie Dialogs Corpus:包含电影剧本中角色之间对话的数据集。它包括 10,000 多对电影角色之间的 200,000 多次对话交流,涵盖了各种主题和类型。
- Ubuntu 对话语料库:寻求技术支持的用户与 Ubuntu 社区支持团队之间的多轮对话集合。它包含超过 100 万个对话,使其成为用于对话系统研究的最大的公开可用数据集之一。
- DailyDialog:各种主题的人与人对话集,从日常生活对话到社会问题讨论。数据集中的每个对话都包含几个回合,并标有一组情绪、情绪和主题信息。
除了这些数据集之外,ChatGPT 还接受了在互联网上发现的大量非结构化数据的训练,包括网站、书籍和其他文本源。这使得 ChatGPT 能够从更一般的意义上了解语言的结构和模式,然后可以针对对话管理或情绪分析等特定应用进行微调。
ChatGPT 是一个独特的模型,它使用与 GPT 系列类似的方法进行训练,但在架构和训练数据方面存在一些差异。ChatGPT 有 15 亿个参数,小于 GPT-3 的 1750 亿个参数。
总体而言,用于微调 ChatGPT 的训练数据通常本质上是对话式的,并且经过专门策划以包括人与人之间的对话,这使 ChatGPT 能够学习如何以对话形式生成自然且引人入胜的响应。
以这种方式思考 ChatGPT 的无监督训练:它被输入大量数据并留给自己的设备来寻找模式并理解所有这些数据。这是允许新的生成人工智能系统如此迅速地扩大规模的机制。
虽然 ChatGPT 的生成 AI 的繁重工作由预训练完成,但它还必须能够理解问题并从所有数据中构建答案。这是由推理阶段完成的,推理阶段由自然语言处理和对话管理组成。
人类参与预训练怎么样?
尽管非监督预训练具有固有的可扩展性,但有一些证据表明,在准备供公众使用的 ChatGPT 过程中可能涉及人工协助。
《时代》杂志的一篇文章中透露了一个重大消息,该文章讨论了在肯尼亚使用每小时收入 1.32 美元至 2 美元的人工“数据标注员”的情况。据时代周刊报道,这些工作人员有责任扫描恐怖和露骨的互联网内容,并将其标记为 ChatGPT 培训。
另一篇发表在 AI 时事通讯 Martechpost 上的文章指出,大型语言模型是使用一种称为从人类反馈中强化学习 (RLHF) 的过程进行训练的。根据这篇文章,“训练过程涉及使用监督学习微调的初始模型,人类训练师同时扮演用户和人工智能助手的角色。”
当谈到“培训”这个词的含义时,这里有一些微妙之处。根据 ChatGPT 本身的说法,“OpenAI 没有使用带有人类反馈的强化学习来训练我。相反,我是结合使用无监督和监督学习技术(例如语言建模、自动编码和序列预测)对我进行预训练的。我的培训涉及处理来自互联网的大量文本数据,这使我能够学习单词和短语之间的模式和关系。”
人工智能继续说道,“然而,一旦我接受了预训练,研究人员和开发人员就可以使用强化学习和人类反馈来针对特定任务或领域对我进行微调,例如回答问题或生成文本。在这些情况下,人类可以提供以奖励或惩罚的形式反馈,可用于更新我的参数并提高我在未来类似任务中的表现。”
这似乎符合 Marktechpost 和 TIME 的报告,因为最初的预训练是无监督的,允许将大量数据输入系统。但是在构建与用户交流的对话响应时(更多内容见下文),响应引擎显然接受了响应类型方面的培训,并接受了过滤掉不当材料的培训——而且这种培训似乎是在人工协助下进行的。
我联系了 OpenAI(ChatGPT 的制造商)进行澄清,但尚未得到回复。如果公司回复我(在 ChatGPT 本身之外),我会用它的答案更新文章。
自然语言处理
自然语言处理(NLP) 侧重于使计算机能够理解、解释和生成人类语言。随着数字数据的指数级增长和自然语言界面的使用越来越多,NLP 已成为许多企业的关键技术。
NLP 技术可用于广泛的应用,包括情感分析、聊天机器人、语音识别和翻译。通过利用 NLP,企业可以自动执行任务、改善客户服务并从客户反馈和社交媒体帖子中获得有价值的见解。
另外: 纽约时报和其他人对 ChatGPT 的严重误解
实施 NLP 的主要挑战之一是处理人类语言的复杂性和歧义性。NLP 算法需要在大量数据上进行训练,以便识别模式和学习语言的细微差别。它们还需要不断完善和更新,以跟上语言使用和上下文的变化。
该技术的工作原理是将语言输入(例如句子或段落)分解为更小的部分,并分析它们的含义和关系以产生见解或回应。NLP 技术结合使用统计建模、机器学习和深度学习等技术来识别模式并从大量数据中学习,以便准确地解释和生成语言。
对话管理
您可能已经注意到,ChatGPT 可以提出后续问题来阐明您的意图或更好地了解您的需求,并提供考虑到整个对话历史的个性化回复。
这就是 ChatGPT 如何以一种感觉自然且引人入胜的方式与用户进行多轮对话。它涉及使用算法和机器学习技术来理解对话的上下文,并在与用户的多次交流中维护它。
对话管理是自然语言处理的一个重要方面,因为它允许计算机程序以一种感觉更像是对话而不是一系列一次性交互的方式与人交互。这有助于与用户建立信任和互动,并最终为使用该程序的用户和组织带来更好的结果。
营销人员当然希望扩大信任的建立方式,但这也是一个可能被证明是可怕的领域,因为这是人工智能可能能够操纵使用它的人的一种方式。
现在你知道了
尽管我们推出了 2,500 个单词,但这仍然是对 ChatGPT 内部发生的所有事情的非常基本的概述。也就是说,也许现在您对这项技术在过去几个月里爆炸式增长的原因有了更多的了解。这一切的关键在于数据本身不受“监督”,人工智能能够获取输入的内容并理解它。
非常棒,真的。
最后,我将整篇文章的草稿提供给 ChatGPT,并要求 AI 用一句话描述这篇文章。干得好:
ChatGPT 就像谷歌和 Wolfram Alpha 的聪明表亲,可以做他们做不到的事情,比如编写故事和代码模块。
ChatGPT 应该是一种没有自我的技术,但如果这个答案不只是让你有点毛骨悚然,那你就没有注意。